


What role do web archives play in history? What is the impact of the development of artificial intelligence (AI) and the increasingly rapid and easy creation of content? Interview with Sophie Gebeil, lecturer in contemporary history at the Laboratoire Temps, espaces, langages, Europe méridionale, Méditerranée (AMU/CNRS), and a specialist in web archives.
Reading time: 8 minutes
Why do we archive the web?
Web archiving means collecting, safeguarding and transmitting content published online and on social networks, from a heritage perspective. Using a web archive is like using a search engine, with the possibility of seeing the evolution of websites over time by browsing through the different versions collected.
Internet Archive, a US platform, is the oldest web archive in the world. In France, institutions became interested in web archiving in the early 2000s. Then, in 2003, UNESCO recognized the Web as part of its heritage with the Charter on the Preservation of Digital Heritage. The web is now part of humanity's heritage.
Since 2006, the Bibliothèque nationale de France (BNF) and the Institut national de l'audiovisuel (INA) have shared responsibility for archiving the French web. Unlike in the United States, web archiving in France is comprehensive and dependent on legal deposit. No one can oppose the collection of online content. Due to legal deposit, these archives can only be consulted in accredited offices, on dedicated workstations.
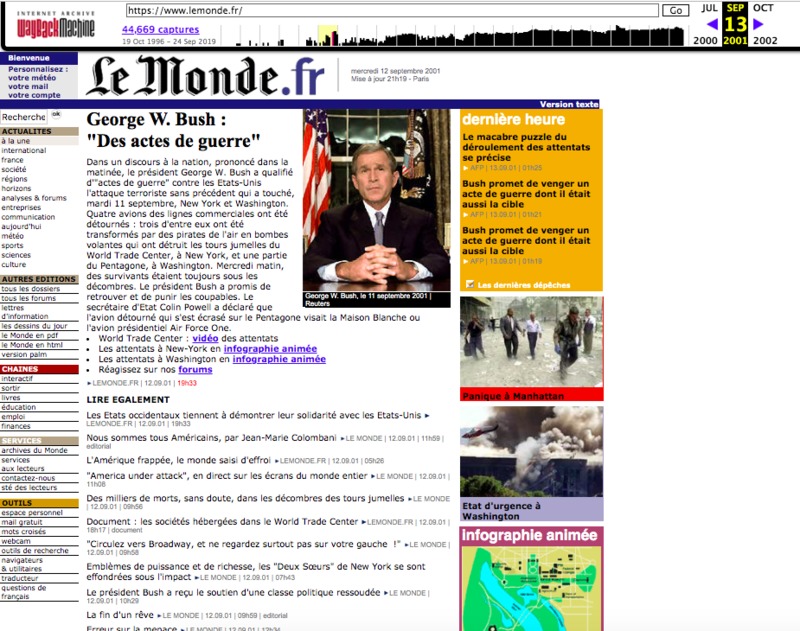
September 11, 2001 terrorist attack, a global event in the age of the Internet - Lemonde.fr home page September 13, 2001
Quotidien Le Monde, www.lemonde.fr, "Attaque terroriste du 11 septembre 2001, événement global à l'ère d'Internet - Page d'accueil du site Lemonde.fr le 13 septembre 2001," 80 documents à la une , accessed February 28, 2024, https://80docsalaune.nakalona.fr/items/show/73.
The attacks of September 11, 2001 are a major event in contemporary history. For researchers working on media and the Web, it was also the first event of global proportions to be visually remembered on the Web. Images of the fire and the collapse of the towers, victims' testimonies and press articles are all circulating there. Conspiracy theories were also born, and are still online today. The Web Archive traces the genealogy of the visual memory of the event on the Web and the associated readings of the world. The Web was then transformed into a Memorial space with the oral history project supported by the 9/11 Memorial Museum and its website.
Why use web archives in history?
I'm a historian of the present. I study media history, the representations and discourses produced by different media, applied to the Web in the 2000s. My thesis focused on the online representation of North African immigration. How are representations of marginalized and minority memories evolving on the French web? How are these memories made visible on the past web? To carry out this work, I need to be able to track down sources. But web content has a short lifespan. It's volatile, changing and disappearing. Using web archives means finding websites from the past and stabilizing your corpus of study.
In the context of our research, the corpus needs to be perennial, so that it can be studied again later. It's a question of respecting historical methodology and the administration of proof. In history, relying solely on "living" web sources is problematic, as it breaks the contract of truth between the historian and the reader, who must always have access to the sources.
Is there a hierarchy of content in web archiving?
Historically, archives have been seen as places of preservation and transmission. Since the second half of the 20th century, this vision has broadened to include administrative documents as well as literary works. Then, the archive opened up to radio, TV and finally the web. This means that, beyond the classic vision of an administrative or scholarly archive, in France it has long been the place for collecting media and popular heritage. The web is part of this history. We are extremely fortunate to benefit from the legal framework of legal deposit, which is rare in most countries. As a result, there is no hierarchy as to what deserves to be archived or not. For archivists, there is no exclusion. However, in practice, archiving is very costly in terms of human time and server storage, and therefore cannot be comprehensive.
Yet the exhaustiveness of the collection is important for tomorrow's historians. If we start selecting information for archiving according to particular criteria, we risk running out of traces. This is why archivists document selection criteria when they are applied, and why several projects allow researchers to deposit their web corpus.
With the rise of artificial intelligence, is there a question mark over the origin and reliability of sources?
It depends on what we mean by "artificial intelligence". Are we talking about the technological movement to create machines capable of learning, or about the automated text generation tools available online, such as ChatGPT, which make it possible to create content ever more quickly and easily?
From the point of view of web archiving in France, it's the place where the content was published that takes precedence. Content posted on ARTE.tv, for example, will be collected, even if it was created by AI. The collection software targets by URL and sucks up all content. There is no further search or rejection.
We've seen that the BNF and INA collect magazines, books, video games, cinema, radio, and television. Preserving everything means that misinformation and a diversity of points of view can also be found. The historian's role when working on a source is to be critical of it. This involves cross-referencing sources and proposing an interpretation of the facts that comes close to a form of historical veracity. Historians are accustomed to this kind of criticism, but not to natively digital documents.
An automatically generated text necessarily relies on other texts, and this is not a problem, because in history, everything can be a source. However, the anonymity of the source can make it difficult to exploit, as it is the historian's job to study who created the content, why, under what conditions, and how it was received.
In the long run, however, if we want to study an event and the only traces left of it are automatically generated texts, this could be a problem. This invites us to participate in interdisciplinary research based on automated tools, using AI processes, capable of identifying the automated nature of a document's creation, as anti-plagiarism software already does.
What impact does artificial intelligence have on your work as a historian?
We've seen that automated text generation tools can have an impact on the historian's questioning of the origin of its sources, but we use other types of AI on a daily basis in our research.
When we have a web corpus to archive with a large collection of web pages, artificial intelligence enables us to process the data and extract trends. AI algorithms and systems allow us to mine the data and support our analysis. For example, I used them in my work on the commemorations of the 1983 march for equality and against racism. The visual recognition tool is used to analyze the corpus of web videos. By recognizing the various key marchers and their frequency of appearance, we can parallel the information with their media coverage.
Given the ephemeral nature of online content, are there any "guardians of the web"?
This is precisely the role of the web archive. But that still raises questions. If you create a new website tomorrow, who's going to care about preserving it in 10 or 15 years' time? Admittedly, this may fall within the realm of the BNF or INA, but the site may escape national collection, which, as we've seen, cannot be comprehensive.
We need to raise awareness among students who include YouTube videos in their corpus, for example. If these videos have disappeared in two months' time, what can we do? Raising awareness helps to put best practices in place. There are tools available for notifying institutions of the collection of their archives. At an institutional level, we're used to thinking about our printed archives and our heritage, but we also need to think about our digital productions. We could ourselves become the guardians of our digital heritage and its transmission.
Precisely how can universities get to grips with the issue of digital archiving?
We're already working on setting up an exploratory experiment in the region. With the Centre de formation et de soutien aux données de la recherche (CEDRE), we're working on a proof-of-concept for the feasibility of collecting and archiving data from an AMU website. What methodology should be used? How can it be made searchable? What role will university libraries play in supporting users? It's all still to be worked out.
Taking advantage of the visit of Niels Brügger, professor at the University of Aarhus (Denmark), a pioneer in the use of web archives in the humanities and social sciences, a symposium entitled "Collecting, using and safeguarding the Web for teaching and research" will take place on March 11 and 12, 2024 at the Inspé in Aix-en-Provence. The aim of the meeting is to reflect on the scientific and educational issues involved in collecting, using and preserving Web archives, while offering practical workshops. It also aims to develop web archiving practices within Aix-Marseille University, thus extending the momentum generated by the RESAW conference conference (MUCEM, June 2023). Registration is free, but compulsory.
These two days are organized by Sophie Gebeil (UMR7303 TELEMMe AMU-CNRS/Visual studies and digital humanities workshop), member of the IUF, as part of the PICCH research program research program and with the support of the RESAW 2023 conference held last June in Marseille.
Contact à ajouter
Informations complémentaires
Interview by Fanny Trifilieff.
Article published on February 28, 2024.
Discover also





Share on social media or




