


Quelle place occupent les archives du web en histoire ? Quel impact a le développement de l’intelligence artificielle (IA) et la création toujours plus facile et rapide de nombreux contenus ? Entretien avec Sophie Gebeil, maîtresse de conférences en histoire contemporaine au Laboratoire Temps, espaces, langages, Europe méridionale, Méditerranée (AMU/CNRS), et spécialiste des archives du web.
Temps de lecture : 8 minutes
Pourquoi archiver le web ?
Archiver le web, c’est effectuer la collecte, la sauvegarde et la transmission du contenu publié en ligne et sur les réseaux sociaux dans une perspective patrimoniale. Consulter une archive web, c’est comme consulter un moteur de recherche avec la possibilité de voir l’évolution des sites web au cours du temps en naviguant à travers les différentes versions collectées.
Internet Archive, une plateforme états-unienne, est la plus vieille archive web au monde. En France, les institutions se sont intéressées à l’archivage du web au début des années 2000. Puis le web a été reconnu comme patrimoine par l’UNESCO en 2003 avec la charte sur la conservation du patrimoine numérique. Le web fait donc partie du patrimoine de l’humanité.
Depuis 2006, la Bibliothèque nationale de France (BNF) et l’Institut national de l’audiovisuel (INA) se partagent l’archivage du web français. Contrairement aux Etats-Unis, en France, l’archivage web est exhaustif et dépend du dépôt légal. On ne peut pas s’opposer à la collecte du contenu mis en ligne. Dû au dépôt légal, la consultation de ces archives se fait donc uniquement dans les lieux accrédités, sur des postes dédiés.
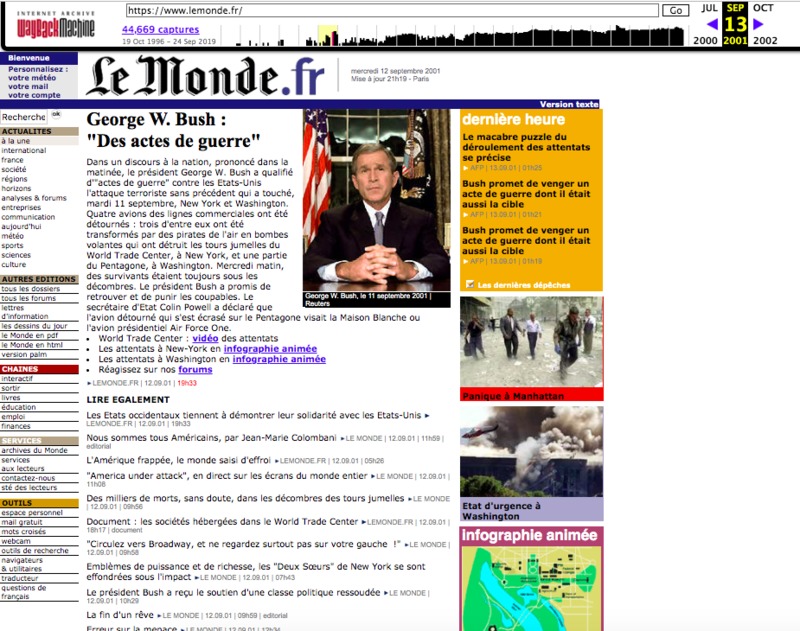
Attaque terroriste du 11 septembre 2001, événement global à l'ère d'Internet - Page d'accueil du site Lemonde.fr le 13 septembre 2001
Quotidien Le Monde, www.lemonde.fr, “Attaque terroriste du 11 septembre 2001, événement global à l'ère d'Internet - Page d'accueil du site Lemonde.fr le 13 septembre 2001,” 80 documents à la une , consulté le 28 février 2024, https://80docsalaune.nakalona.fr/items/show/73.
Les attentats du 11 septembre 2001 constituent un événement majeur de l'histoire contemporaine. Pour les chercheur-e-s qui travaillent sur les médias et le Web, il s'agit aussi du premier événement d'ampleur mondial dont la mémoire visuelle se construit aussi sur le Web. Les images de l'incendie et de l'effondrement des tours, les témoignages des victimes, les articles de presse y circulent. Naissent aussi des théories complotistes qui sont encore aujourd'hui toujours en ligne. Les Archives du Web permettent de retracer la généalogie de la mémoire visuelle de l'événement sur le Web et des lectures du monde qui y sont associées. La Toile s'est ensuite transformé en espace Mémorial avec le projet d'histoire orale portée par le 9/11 Memorial Museum et son site Web.
Pourquoi utiliser les archives web en histoire ?
Je suis historienne du temps présent. J’étudie l’histoire des médias, les représentations et discours produits par les différents médias, appliqués au Web des années 2000. Ma thèse portait sur la représentation de l’immigration maghrébine en ligne. Comment les représentations de mémoire marginalisées et minoritaires sur le web français évoluent-elles ? Comment ces mémoires sont mises en visibilité sur le web passé ? Pour effectuer ce travail, je dois être en capacité de retrouver des sources. Or la durée de vie des contenus web est courte. Ils sont volatils, se transforment et disparaissent. Utiliser les archives du web, c’est retrouver des sites web du passé et stabiliser son corpus d’étude.
Dans le cadre de nos recherches, il faut que le corpus soit pérenne, qu’il puisse être réétudié plus tard. Il en va du respect de la méthodologie de l’histoire et de l’administration de la preuve. En histoire, s’appuyer uniquement sur des sources du web « vivant » est problématique, car cela brise le contrat de vérité entre l’historien et le lecteur qui doit pouvoir toujours accéder aux sources.
Existe-t-il une hiérarchisation des contenus lors de l’archivage web ?
Historiquement, les archives sont vues comme des lieux de conservation et de transmission. Depuis la deuxième moitié du XXème siècle, la vision s’est élargie et on y retrouve autant de documents administratifs que d’œuvres littéraires. Puis, l’archive s’est ouverte à la radio, la TV et enfin au web. Cela veut dire qu’au-delà de la vision classique d’une archive administrative ou savante, en France, elle est depuis longtemps le lieu de collecte du patrimoine médiatique et populaire. Le web s’inscrit dans cette histoire-là. Nous avons la chance énorme de bénéficier du cadre juridique du dépôt légal, ce qui est rare dans la plupart des pays. Il n’y a donc pas de hiérarchisation sur ce qui mérite d’être archivé ou non. Pour les archivistes, il n’y a donc pas d’exclusion. Cependant, dans les faits, l’archivage est très coûteux en temps humain et en stockage sur les serveurs, et par conséquent, il ne peut être exhaustif.
Pourtant l’exhaustivité de la collecte est importante pour les historiens de demain. Si on commence à sélectionner les informations à archiver selon des critères particuliers, nous risquons de manquer de traces. C’est pourquoi les archivistes documentent les critères de sélection lorsqu’elle a lieu, et que plusieurs projets permettent aux chercheurs de déposer leur corpus web.
Avec la montée de l’intelligence artificielle, y a-t-il un questionnement sur l’origine et la fiabilité des sources ?
Cela dépend ce qu’on entend par « intelligence artificielle ». Parle-t-on du mouvement technologique qui vise à créer des machines capables d’apprendre, ou bien des outils de génération de texte automatisés disponibles en ligne comme ChatGPT, qui permettent de créer du contenu toujours plus rapidement et facilement ?
Du point de vue de l’archivage web en France, c’est l’endroit où a été publié le contenu qui prime. Un contenu posté sur ARTE.tv par exemple, sera collecté, même s’il a été créé par IA. Le logiciel de collecte cible par URL et aspire l’ensemble des contenus. Il n’y a pas de recherche plus fine ou de rejet.
Nous avons vu que la BNF et l’INA collectent autant les magazines, que les livres, les jeux vidéo, le cinéma, la radio ou encore la télévision. Tout conserver, ça veut dire qu’on y retrouve aussi des informations erronées et une diversité de points de vue. Le rôle de l’historien quand il travaille sur une source est d’en faire une critique documentaire. Il s’agit de croiser les sources et proposer une interprétation des faits qui se rapproche d’une forme de véracité historique. L’historien est habitué à faire cette critique, mais peu habitué aux documents nativement numériques.
Un texte généré automatiquement s’appuie forcément sur d’autres textes, et ce n’est pas un problème, car en histoire, tout peut-être une source. Cependant, l’anonymat de la source peut le rendre difficile à exploiter, car c’est le travail même de l’historien d’étudier qui est à l’origine d’un contenu, pourquoi, dans quelles conditions ou encore la réception qui en est faite.
A terme, on peut quand même se dire que si on veut étudier un événement et que les seules traces qui en restent sont des textes générés automatiquement, cela pourrait poser problème. Cela nous invite à participer à des recherches interdisciplinaires à partir d’outils automatisés, utilisant les procédés de l’IA, capables de repérer le caractère automatisé de la création d’un document comme le font déjà des logiciels anti-plagiats.
Quel impact l’intelligence artificielle a-t-elle sur votre travail d’historienne ?
Nous avons vu que les outils de génération de texte automatisés peuvent avoir un impact sur le questionnement de l’historien quant à l’origine de ses sources, mais nous utilisons d’autres types d’IA au quotidien dans nos recherches.
Lorsque nous avons un corpus web à archiver avec une grande collection de pages web, l’intelligence artificielle permet de traiter les données et d’en extraire des tendances. Les algorithmes et les systèmes d’IA permettent de fouiller les données et d’accompagner notre analyse. Par exemple, je m’en suis servie lors de mon travail sur les commémorations de la marche pour l’égalité et contre le racisme de 1983. L’outil de reconnaissance visuelle permet d’analyser le corpus de vidéos web. En reconnaissant les différents marcheurs clés et leur fréquence d’apparition, on peut mettre l’information en parallèle avec leur médiatisation.
Face au caractère éphémère des contenus en ligne, existe-t-il des « gardiens du web » ?
Ce rôle, c’est justement celui de l’archive web. Mais ça pose encore question. Si demain, vous créez un nouveau site internent, qui se sera soucié de sa conservation dans 10 ou 15 ans ? Certes, cela peut relever du travail de la BNF ou de l’INA, mais le site peut échapper à la collecte nationale qui ne peut être exhaustive comme nous l’avons vu.
Il y a un tout un travail de sensibilisation à effectuer auprès des étudiants qui intègrent des vidéos YouTube dans leur corpus, par exemple. Si dans deux mois celles-ci ont disparu, que fait-on ? La sensibilisation permet de mettre en place des bonnes pratiques. Il existe des outils qui permettent de signaler aux institutions la collecte de leurs archives. Au niveau institutionnel, on a l’habitude de réfléchir à nos archives imprimées et à notre patrimoine, mais il faudrait aussi réfléchir à nos productions numériques. On pourrait devenir nous-même les gardiens de notre patrimoine numérique et de sa transmission.
Justement, comment l’université peut-elle s’emparer de ces questions d’archivage du numérique ?
Nous travaillons déjà sur la mise en place d’une expérience à titre exploratoire sur le territoire. Avec le Centre de formation et de soutien aux données de la recherche (CEDRE), nous travaillons sur une preuve de concept de la faisabilité de la collecte et l’archivage d’un site web AMU. Quelle méthodologie utiliser ? Comment le rendre consultable ? Quel sera le rôle des bibliothèques universitaires dans l’accompagnement des usagers ? Tout reste à construire.
Profitant de la venue de Niels Brügger, professeur à l’Université d’Aarhus (Danemark), pionnier dans l’utilisation des archives du web en sciences humaines et sociales, une journée d'études intitulée « Collecter, utiliser et sauvegarder le Web pour l’enseignement et la recherche » aura lieu les 11 et 12 mars 2024 à l’Inspé d’Aix-en-Provence. Cette rencontre devra permettre de réfléchir aux enjeux scientifiques et éducatifs liés à la collecte, à l’utilisation et à la conservation des archives du Web tout en proposant des ateliers de mise en pratique. Elle s’inscrit aussi dans la perspective de développer les usages liés à l’archivage du web au sein d’Aix-Marseille Université, prolongeant ainsi la dynamique impulsée suite à la conférence RESAW (MUCEM, juin 2023). L’inscription est gratuite, mais obligatoire.
Ces deux journées sont organisées par Sophie Gebeil (UMR7303 TELEMMe, AMU-CNRS/Atelier Visual studies et Humanités numériques), membre de l’IUF, dans le cadre du programme de recherche PICCH et avec le soutien de l’équipe d’organisation de la conférence RESAW 2023 qui s’est tenue en juin dernier à Marseille.
Contact à ajouter
Informations complémentaires
Propos recueillis par Fanny Trifilieff.
Article publié le 28 février 2024.
A découvrir aussi





Partagez sur les réseaux ou




